Coordinator Resilience
The coordinator is a single, long-lived LLM session. If it wedges — a provider stops streaming, an SDK send never returns, or an autopilot stalls at a zero-active-worker boundary — the whole fleet appears frozen. agents-fleet ships a layered defence so a stuck coordinator is detected, surfaced, and recovered without a human babysitting the terminal.
This page documents that machinery: the five-tier stall ladder, the watchdog and recovery path, the autopilot wake/escalation subsystems, the heartbeat monitor's bridged exemption, every killswitch, and the diagnostic commands.
The implementation lives in src/coordinator/CoordinatorWatchdog.ts, src/coordinator/CompletionWaker.ts, src/coordinator/AutopilotEscalationNotifier.ts, and src/fleet/HeartbeatMonitor.ts.
The five-tier stall ladder
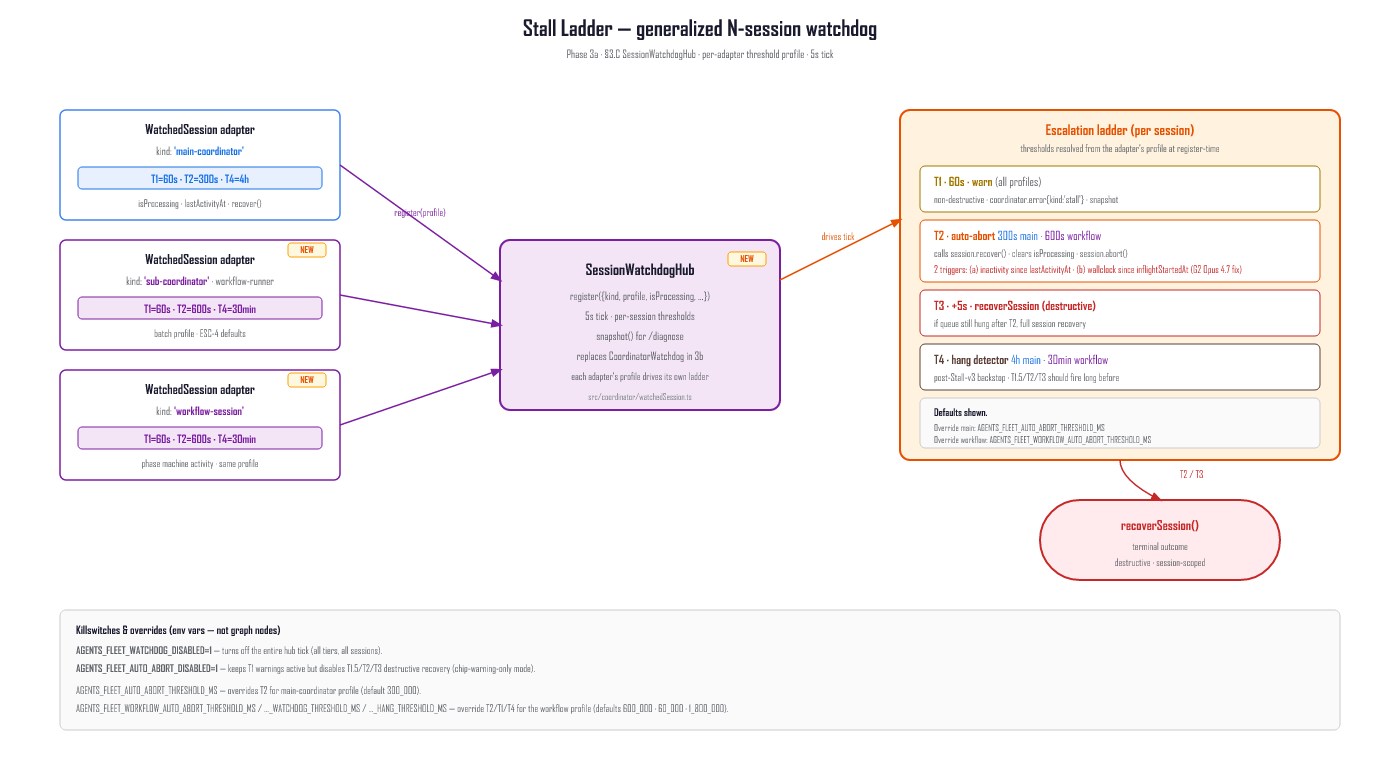
A single CoordinatorWatchdog interval (default 10 s cadence, .unref()-ed so it never blocks process exit) drives an escalating ladder. Each tier is strictly more aggressive than the last, and the earlier (non-destructive) tiers are designed to fire long before the destructive ones.
| Tier | Trigger | Action | Destructive? |
|---|---|---|---|
| T1 — warn | 60 s of isProcessing=true with no SDK activity | Emit coordinator.error with kind stall, persist to the EventLog, notify channels, write a diagnostic snapshot | No |
| T1.5 — zombie probe | lastActivityAt frozen for ~24 min (scales with autoAbortThresholdMs * 0.6 / checkInterval, floor 3 ticks) | Fast-path to recoverSession() | Yes |
| T2 — auto-abort | 40 min stalled (AGENTS_FLEET_AUTO_ABORT_THRESHOLD_MS) | Emit coordinator.error kind auto-abort, reset the user-input wait, clear isProcessing, call session.abort(), schedule T3 | Yes |
| T3 — escalation | +5 s after T2 if the queue is still hung | Call recoverSession() | Yes |
| T4 — hang detector | 4 h (AGENTS_FLEET_HANG_THRESHOLD_MS, lives in SessionSendQueue) | Throw FleetError('TIMEOUT'), routed to onSessionRecovery via withRecovery | Yes |
T1 — warn (60 s)
When the coordinator has been marked isProcessing for 60 s with no observed SDK activity, the watchdog emits a coordinator.error event tagged stall, persists it to the EventLog, notifies any attached channels (so a remote operator sees it), and writes a diagnostic snapshot. T1 is non-destructive — it is a warning chip, nothing is aborted. While a stall window is open the watchdog also fires a repeating "still stalled" heartbeat ping (default every 5 min, AGENTS_FLEET_STALL_HEARTBEAT_MS) and a closing message once the window resolves.
T1.5 — zombie probe (~24 min)
A genuinely wedged session can keep isProcessing true while lastActivityAt never advances. The zombie probe watches for lastActivityAt being frozen across a number of consecutive ticks derived from autoAbortThresholdMs * 0.6 / checkInterval (floored at 3 ticks). At the 40 min T2 default this works out to roughly 24 min. When it trips, it fast-paths straight to recoverSession() rather than waiting for the full T2 window.
#492 — pre-stream waits cannot suppress recovery
The isAwaitingFirstDelta predicate is capped at autoAbortThresholdMs. A wedged provider stuck before its first delta can no longer suppress T1.5/T2 indefinitely — past the cap, recovery tiers fire regardless. This closed a silent-stall regression.
T2 — auto-abort (40 min)
After 40 min of an unbroken stall the watchdog performs the first heavy intervention: it emits coordinator.error kind auto-abort, calls sendQueue.resetUserInputWait(), clears isProcessing, calls session.abort(), and schedules T3. The 40 min default (raised from an earlier 5 min) is sized so that legitimate long batched worker fan-outs — workflow-as-subcoordinator runs commonly wait 10–30 min — don't trip a false-positive abort, while still leaving roughly 6× headroom under the 4 h T4 hang detector.
Override with AGENTS_FLEET_AUTO_ABORT_THRESHOLD_MS (milliseconds).
T3 — escalation (+5 s)
Five seconds after T2, if the send queue is still hung, the watchdog escalates to a destructive recoverSession() — tearing down and rebuilding the coordinator session.
T4 — hang detector (4 h)
The last line of defence lives in SessionSendQueue, not the watchdog. If any single send has not completed after 4 h it throws FleetError('TIMEOUT'), which withRecovery routes to onSessionRecovery. The 4 h default is deliberately far out: T1.5/T2/T3 should have recovered the session long before T4 is ever reached. Override with AGENTS_FLEET_HANG_THRESHOLD_MS.
Recovery and forensics
When a session is recovered, handleRecovered writes a coordinator.recovered event (kind activity or recovery) to the EventLog. The /stall-history command pairs each stall row with its matching recovered row from the coordinator_events table so you can reconstruct exactly what happened and when.
Killswitches
| Env var | Effect |
|---|---|
AGENTS_FLEET_WATCHDOG_DISABLED=1 | All tiers off — the watchdog interval never starts. |
AGENTS_FLEET_AUTO_ABORT_DISABLED=1 | T2 + T1.5 off; T1 warn still fires (chip warnings without destructive recovery). |
AGENTS_FLEET_AUTO_ABORT_THRESHOLD_MS | Override the 40 min T2 threshold (ms). |
AGENTS_FLEET_HANG_THRESHOLD_MS | Override the 4 h T4 hang threshold (ms). |
AGENTS_FLEET_STALL_HEARTBEAT_MS | Override the 5 min stall-heartbeat cadence (ms). |
Precedence: WATCHDOG_DISABLED wins (interval never starts, no tier can fire); AUTO_ABORT_DISABLED turns off T2 + T1.5 while leaving T1 warnings intact.
Diagnostics
/diagnose(or/diagnose --jsonfor PII-redacted output) surfaces live watchdog state, including theautoAbortthreshold,autoAbortFires,zombieProbes, andlastReasoncounters./stall-historypairs stall and recovered rows fromcoordinator_eventsfor post-mortem forensics.
Autopilot progress and escalation
Multi-stage autopilots can stall at a zero-active-worker boundary — every worker has finished, the coordinator is idle, but outstanding work remains and nothing nudges it forward. Three subsystems close that "silent freeze" gap.
CompletionWaker
src/coordinator/CompletionWaker.ts listens for terminal agent events. When the coordinator is idle, there are zero active workers, and outstanding work exists, it enqueues exactly one debounced (1500 ms) wake prompt. A no-progress cap (three consecutive identical-signature wakes) latches a stuck state and emits an autopilot.stuck event. The latch re-arms on forward progress — when the progress signature changes, wake-on-completion resumes, so the system recovers after a stuck episode rather than giving up.
Killswitch: AGENTS_FLEET_WAKE_ON_COMPLETION (default ON; set to 0 to disable).
AutopilotEscalationNotifier
src/coordinator/AutopilotEscalationNotifier.ts subscribes to autopilot.stuck and to bridged agent.stalled events flagged bridged: true. For each stuck episode it fans out one channel notification (ChannelHub.notifyAutopilotStuck) plus one in-app chip — so a stuck autopilot reaches a remote operator instead of sitting silently.
Killswitch: AGENTS_FLEET_AUTOPILOT_ESCALATION (default ON; set to 0 to disable the notify + chip).
HeartbeatMonitor — bridged exemption
src/fleet/HeartbeatMonitor.ts normally kills workers whose tool/token/activity signals go quiet. But bridged sub-coordinator shells (role bridged-sub-coord or isStageCoordinator === true) have structurally frozen signals, so a blanket kill would be a false positive. Those shells are exempt from the normal heartbeat kill.
Genuine bridged stalls are instead detected via FleetManager.getBridgedProgress, which reports stage index, last stage-transition time, and agents spawned. Past a long threshold (default 45 min) the monitor emits a non-destructiveagent.stalled event flagged bridged: true — it does not kill the shell.
To prevent evasion of the unrecoverable-stall accounting, the respawn-count decrement (FR-14) is gated on genuine progress: toolUseCount or tokenCount strictly increasing. A bare lastActivity timestamp bump, or a respawned worker whose counters reset, does not shed respawn credit.
Killswitches:
| Env var | Effect |
|---|---|
AGENTS_FLEET_HEARTBEAT_BRIDGED_EXEMPT | Default ON; set to 0 to restore the legacy kill behavior. |
AGENTS_FLEET_HEARTBEAT_BRIDGED_STALL_MS | Override the 45 min bridged-stall threshold (ms). |
Related events
The resilience subsystems emit these FleetEvents (see src/types/state.ts):
coordinator.error— kindsstall(T1) andauto-abort(T2).coordinator.recovered— kindsactivityandrecovery.autopilot.stuck— CompletionWaker latched a no-progress stall.agent.stalled— now carries an optionalbridgedflag for bridged shells.
See also
- Sessions and Persistence — the session schema,
--resume, and the exit/shutdown pipeline. - Worker Views — the chip strip where stall warnings surface.
- Multi-Instance — isolating concurrent fleets.